
Michael Pidd and Katherine Rogers
The mixed data challenge
One of the challenges for a mixed methods project such as the AHRC-funded Beyond the Multiplex is that it produces mixed data – data that is different in its file format, structure, and content. There is a longitudinal survey (nominal data) which takes three snapshots of people’s film viewing habits over time; a socio-cultural index which profiles a population’s cultural habits based on a range of national lifestyle surveys (statistical data); semi-structured interviews with cinema-goers and industry experts (natural language data in audio format); and focus groups which use film elicitation methods to prompt cinema-goers to reflect on meaning in film (again, natural language data in audio format).
Each type of data has a research value in its own right, and will help us address specific research questions. For example, the longitudinal survey enables us to understand how film viewing habits change over time, whilst film elicitation focus groups enable us to understand how cinema-goers construct meaning from film. This is all well and good for siloed research questions, but the project is more ambitious than this, seeking to answer questions that cannot be answered by any one individual type of data alone.
So the number one challenge for a mixed methods project is: how can we capture and interrogate mixed data consistently, such that we can submit one question to the entire collection of data and be given meaningful results? The solution is an ontology.
What is an ontology?
Apart from its pretentious sounding name and its tendency to attract contempt from Philosophy colleagues (all good reasons for using the term, in my view), an ontology is a data model which describes all the components and characteristics of a particular knowledge domain. In Beyond the Multiplex, our ontology describes the domain of film, cinema, and cinema-going using three simple classes of information: entities, the characteristics of entities, and relationships between entities. For example: film is an entity; it has characteristics such as a title, plot, characters, duration, media; it has relationships to other entities such as actors, venues, and cinema-goers; and each of these entities has its own characteristics and further relationships. Note that this is a data model — it is not data, nor is it a database. It is purely conceptual.
Data models are used to dictate how data is described, structured, and related. For example, a relational database uses a relational data model. But an ontology goes beyond a traditional relational model. Relational data models enable us to create relationships between entities, such as film->venue if we wanted to describe which films were shown in which venues, but this does not tell us what the relationship is – it merely tells us that two entities are related, and we are required to infer the nature of this relationship. An ontology elaborates a relational data model by defining relationships explicitly. For example: film->was shown at->venue. In this model, we have named three parts of the relationship: we have named the two related entities (film and venue), and we have named what the relationship is (was shown at). We can use the same structure for capturing the characteristics of entities: film->is called->title and film->has character->ET. In information science this tri-part structure is often referred to as a triple or subject-predicate-object.
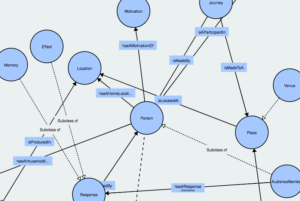
You can see a visualisation of the ontology which we have designed for Beyond the Multiplex. Film and person are unsurprisingly at the centre of an ontology which is concerned with the relationships between film and their audiences. Organisation is also an important entity, because it relates to those organisations that define policy with respect to film and audience, and those organisations that screen films or organise film related events. A person has relationships with real-world objects (named entities) such as location and film; socio-cultural phenomena such as cultural activity and audience; and behavioural characteristics such as motivation, memory, and response (e.g. a person’s response to watching a film). This type of structure enables us to link a person to both qualitative and quantitative data, allowing a person’s behaviour, not only with respect to film consumption, but also other cultural activities, either to be viewed within an individual context or as part of a larger socio-economic group. Each entity also has characteristics, such as the title of a film. In many instances these characteristics are underpinned by formal taxonomies, such as film titles. The ontology is not a final version – it is intended to identify the key entities and relationships, and evolve as more data is collected to more accurately model the domain.
Why is an ontology useful for mixed data?
First, it enables us to store and interrogate mixed data consistently. The conventional approach to mixed data is to analyse statistical data using spreadsheet-like software such as SPSS and then separately analyse natural language data using qualitative software such as NVivo and MaxQData. Although NVivo abnd MaxQData now allow users to work with statistical data alongside qualitative data, they are slow when analysing large datasets. An ontology enables us to apply the same data model to all data types, thereby enabling us to interrogate all data types in the same way, simultaneously. Of course this requires us to transform all our data into the ontology, which is where much of the labour is required for this type of project (more on this later).
Second, it enables us to infer relationships across the different data types. For example, an attendee of the film elicitation focus groups might express an interest in Asian cinema; an interviewee might cite Asian cinema as their preferred sub-genre of foreign film; and the longitudinal survey might reveal that Asian cinema has a growing audience on digital streaming platforms. The use of a consistent ontology enables us to explore these qualities simultaneously, and to have the qualities arising from one body of data enrich and elucidate our understanding of another body of data. In our example, one might infer that the attendee of the focus group and the interviewee fulfil their interest in Asian cinema using a digital streaming platform at home rather than by attending their local cinema.
Third, and related to my previous point, defining the characteristics of entities and their relationships to one another using a formal model could enable a computer to undertake deductive reasoning. For example, if John->lives in->Hull and John->watches films at->home, whilst Sarah->lives in->Hull and Sarah->watches films at->cinema, the computer could infer that John is able to watch films at a cinema in or near Hull but chooses not to. Although this is straightforward logic for humans, only an ontological data model enables a computer to infer information not explicit within the dataset. When datasets become huge, computer-assisted deduction is helpful for researchers framing questions such as: which people choose to watch films at home rather than going to their local cinema? In our example, there is no information in John’s data to show that there is a cinema in or near Hull – this is inferred from Sarah’s data.
How do we capture mixed data using an ontology – in practice?
So that’s the data model, conceptually. But how do we implement it so that we can start storing data using its structure and rules? First we defined and refined the basic ontology using OWL (Web Ontology Language) as part of an iterative process which involved examination of the source documents and a deepening of our understanding of the project’s research questions. OWL is an XML schema for formally describing ontologies. In essence, it sets out the rules that make up the data model: for example, it identifies what entities, characteristics and relationships are possible within the ontology’s knowledge domain. The schema can then be used to natively encode data as XML documents using XML authoring software, such as XMetaL, or it can be used as the blueprint for a system designed to store and manage ontologically-structured data, such as a database.
In our case we used an OWL visualisation service called WebVOWL that enabled the project team to visualise and critique the ontology, before implementing the ontology using NVivo and a MySQL database. We used NVivo as an authoring environment for encoding our natural language data (full-text transcriptions of interviews, focus groups and policy documents). The project’s researchers developed an NVivo coding structure using nodes (in NVivo terminology) to mirror the ontology. After encoding our data we exported the nodes as an XML extract, and ingested the encoded information into a MySQL database. Crucially, just as the encoded information (our extract of NVivo nodes) mirrors our ontology, the table structure of the MySQL database mirrors our ontology also.
We chose NVivo as an authoring environment for our natural language data because it was user friendly and familiar to the project team, and it enabled the team to interrogate aspects of the data during the process of encoding. Also, as part of the discovery interface which we envisage, it will be important for users interrogating our ontologically-structured data to have the facility to ‘drill down’ into the original transcripts and full texts. The only drawback we have experienced in using NVivo is that relationships between nodes are not included in the extract, and have to be supplied as a separate data file in HTML. Statistical and nominal data (surveys and socio-cultural index) are transformed into structures that reflect our ontology using scripts and then ingested into the MySQL database.
The MySQL database mirrors the ontology by having separate tables that describe our entities, their attributes, and their relationships to one another. Our preference for MySQL as a data storage format is in part due to the ease in which data can be subsequently transformed into other formats and encoding standards (including OWL-encoded XML documents) using SQL, and because we can then audit and quality check the data via a simple interface such as Sonata Admin.
How do we query mixed data using an ontology? Next steps
In the next phase of Beyond the Multiplex we need to explore whether a relational database such as MySQL is the best solution for querying ontologically-structured data, because an ontology results in data that is highly atomised and therefore slow to query in a relational system that has to join all the atoms together each time a query is made. For example, whereas a conventional relational database will have a table called person which contains all the attributes of the person as table columns (e.g. a person table containing the columns name, gender, age etc), an ontologically-structured database will store all the attributes of a person in separate tables (e.g. tables called name, gender, age) and link them to the person table using a relationships table which contains values such as hasName, hasGender, hasAge. The eventual data output will be person->hasName->name, person->hasGender->gender, person->hasAge->age.
The advantages of an ontology for describing complex, mixed data using a simple triples structure have been described above, but the performance issues that arise due to the need for a database query to join together so many atoms of data is forcing us to consider RDF and graph systems such as Neo4j, noSQL databases, and query languages such as SPARQL. Establishing an architecture that enables us to perform quick, efficient, consistent, and complex querying of our data is an essential next step towards designing a discovery interface for Beyond the Multiplex and utilising the value of our ontology. We will report further on this in due course!